Partie 19 : Plus de jointures spatiales¶
Dans la partie précédente nous avons vu les fonctions ST_Centroid(geometry) et ST_Union(geometry) ainsi que quelques exemples simples. Dans cette partie nous réaliserons des choses plus élaborées.
Création de la table de traçage des recensements¶
Dans le répertoire \data\ des travaux pratiques, il y a un fichier qui contient des données attributaires, mais pas de géométries, ce fichier est nommé nyc_census_sociodata.sql. La table contient des données sociaux-économiques intéressantes à propos de New York : revenus financiers, éducation .... Il y a juste un problème, les données sont rassemblées en “trace de recensement” et nous n’avons pas de données spatiales associées !
Dans cette partie nous allons
- Charger la table nyc_census_sociodata.sql
- Créer une table spatiale pour les traces de recensement
- Joindre les données attributaires à nos données spatiales
- Réaliser certaines analyses sur nos nouvelles données
Chargement du fichier nyc_census_sociodata.sql¶
- Ouvrez la fenêtre de requêtage SQL depuis PgAdmin
- Sélectionnez File->Open depuis le menu et naviguez jusqu’au fichier nyc_census_sociodata.sql
- Cliquez sur le bouton “Run Query”
- Si vous cliquez sur le bouton “Refresh” depuis PgAdmin, la liste des tables devrait contenir votre nouvelle table nyc_census_sociodata
Création de la table traces de recensement¶
Comme nous l’avons fait dans la partie précédente, nous pouvons construire des géométries de niveau suppérieur en utilisant nos blocs de base en utilisant une partie de la clef blkid. Afin de calculer les traces de recensement, nous avons besoin de regrouper les blocs en uitlisant les 11 premiers caractères de la colonne blkid.
360610001009000 = 36 061 00100 9000 36 = State of New York 061 = New York County (Manhattan) 000100 = Census Tract 9 = Census Block Group 000 = Census Block
Création de la nouvelle table en utilisant la fonction d’agrégation ST_Union :
-- Création de la table
CREATE TABLE nyc_census_tract_geoms AS
SELECT
ST_Union(the_geom) AS the_geom,
SubStr(blkid,1,11) AS tractid
FROM nyc_census_blocks
GROUP BY tractid;
-- Indexation du champ tractid
CREATE INDEX nyc_census_tract_geoms_tractid_idx ON nyc_census_tract_geoms (tractid);
-- Mise à jour de la table geometry_columns
SELECT Populate_Geometry_Columns();
Regrouper les données attributaires et spatiales¶
L’objectif est ici de regrouper les données spatiales que nous avons créé avec les données attributaires que nous avions chargé initialement.
-- Création de la table
CREATE TABLE nyc_census_tracts AS
SELECT
g.the_geom,
a.*
FROM nyc_census_tract_geoms g
JOIN nyc_census_sociodata a
ON g.tractid = a.tractid;
-- Indexation des géométries
CREATE INDEX nyc_census_tract_gidx ON nyc_census_tracts USING GIST (the_geom);
-- Mise à jour de la table geometry_columns
SELECT Populate_Geometry_Columns();
Répondre à une question intéressante¶
Répondre à une question intéressante ! “Lister les 10 meilleurs quartiers ordonnés par la proportion de personnes ayant acquis un diplôme”.
SELECT
Round(100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total), 1) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Intersects(n.the_geom, t.the_geom)
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
Nous sommons les statistiques qui nous intéressent, nous les divisons ensuite à la fin. Afin d’éviter l’erreur de non-division par zéro, nous ne prenons pas en compte les quartiers qui n’ont aucune personne ayant obtenu un diplôme.
graduate_pct | name | boroname
--------------+-------------------+-----------
40.4 | Carnegie Hill | Manhattan
40.2 | Flatbush | Brooklyn
34.8 | Battery Park | Manhattan
33.9 | North Sutton Area | Manhattan
33.4 | Upper West Side | Manhattan
33.3 | Upper East Side | Manhattan
32.0 | Tribeca | Manhattan
31.8 | Greenwich Village | Manhattan
29.8 | West Village | Manhattan
29.7 | Central Park | Manhattan
Polygones/Jointures de polygones¶
Dans notre requête intéressante (dans Répondre à une question intéressante) nous avons utilisé la fonction ST_Intersects(geometry_a, geometry_b) pour déterminer quelle entité polygonale à inclure dans chaque groupe de quartier. Ce qui nous conduit à la question : que ce passe-t-il si une entité tombe entre deux quartiers ? Il intersectera chacun d’entre eux et ainsi sera inclut dans chacun des résultats.
Pour éviter ce cas de double comptage il existe trois méthodes :
- La méthode simple consiste a s’assurer que chaque entité ne se retrouve que dans un seul groupe géographique (en utilisant ST_Centroid(geometry))
- La méthode complexe consiste à disviser les parties qui se croisent en utilisant les bordures (en utilisant ST_Intersection(geometry,geometry))
Voici un exemple d’utilisation de la méthode simple pour éviter le double comptage dans notre requête précédente :
SELECT
Round(100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total), 1) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Contains(n.the_geom, ST_Centroid(t.the_geom))
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
Remarquez que la requête prend plus de temps à s’exécuter, puisque la fonction ST_Centroid doit être effectuée pour chaque entité.
graduate_pct | name | boroname
--------------+-------------------+-----------
49.2 | Carnegie Hill | Manhattan
39.5 | Battery Park | Manhattan
34.3 | Upper East Side | Manhattan
33.6 | Upper West Side | Manhattan
32.5 | Greenwich Village | Manhattan
32.2 | Tribeca | Manhattan
31.3 | North Sutton Area | Manhattan
30.8 | West Village | Manhattan
30.1 | Downtown | Brooklyn
28.4 | Cobble Hill | Brooklyn
Éviter le double comptage change le résultat !
Jointures utilisant un large rayon de distance¶
Une requête qu’il est “sympa” de demander est : “Comment les temps de permutation des gens proches (dans un rayon de 500 mètres ) des stations de métro diffèrent de ceux qui en vivent loin ? “
Néanmoins, la question rencontre les mêmes problèmes de double comptage : plusieurs personnes seront dans un rayon de 500 mètres de plusieurs stations de métro différentes. Comparons la population de New York :
SELECT Sum(popn_total)
FROM nyc_census_blocks;
8008278
Avec la population des gens de New York dans un rayon de 500 mètres d’une station de métro :
SELECT Sum(popn_total)
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.the_geom, subway.the_geom, 500);
10556898
Il y a plus de personnes proches du métro qu’il y a de personnes ! Clairement, notre requête SQL simple rencontre un gros problème de double comptage. Vous pouvez voir le problème en regardant l’image des zones tampons créées pour les stations.
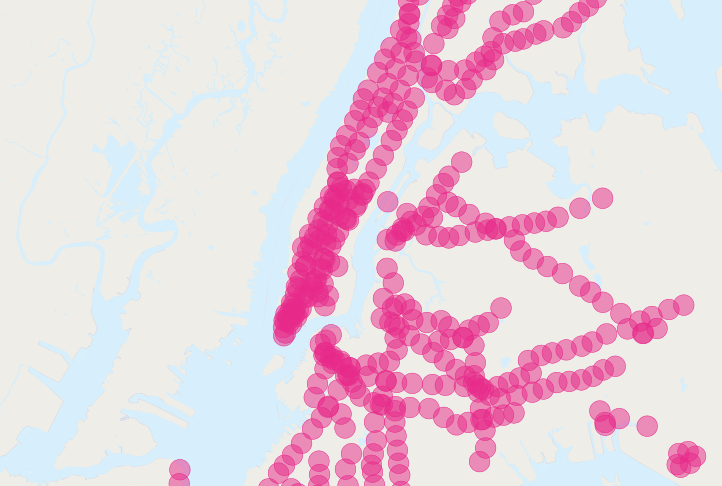
La solution est de s’assurer que nous avons seulement des blocs distincts avant de les regrouper. Nous pouvons réaliser cela en cassant notre requête en sous-requêtes qui récupèrent les blocs distincts, les regroupent pour ensuite retourner notre réponse :
SELECT Sum(popn_total)
FROM (
SELECT DISTINCT ON (blkid) popn_total
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.the_geom, subway.the_geom, 500)
) AS distinct_blocks;
4953599
C’est mieux ! Donc un peu plus de 50 % de la population de New York vit à proximité (500m, environ 5 à 7 minutes de marche) du métro.